
過去3回、開発環境のインストールとプログラミングについて、簡単にお伝えしてきました。今回は Java 初心者用 – 基本用語について、順に解説していきます。(随時更新)
オブジェクト指向: Java関連
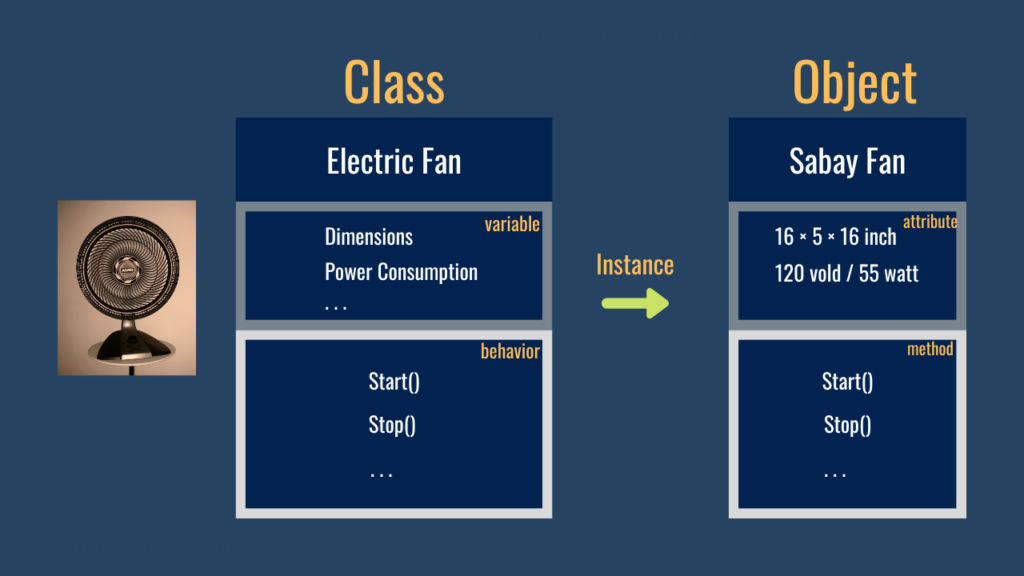
オブジェクト指向
Java ではオブジェクト指向という考え方を採用しています。オブジェクト (object) は「物」「物体」という意味で、とても抽象的な意味の単語です。ここでいうオブジェクトは、後述するクラスから生成された「物」「物体」になります。生成されたオブジェクトが色々な処理を実行します。
クラス (Class)
クラスは、どのようなオブジェクトにするのかを定義にするものです。わかりやすく言えば、クラスとはプログラムの設計図のことです。クラスは属性と振る舞いが定義されています。たとえば、上記の図では扇風機クラスを定義しています。しかし、この扇風機クラスには消費電力などの具体的な数値などは記載されておりません。この枠組みだけのものがクラスになります。
属性 (attribute)
クラスの中で定義されるオブジェクトの「状態」や「データ」を表すものを属性といいます。プログラミング内ではフィールドや変数と呼ばれることもあるので注意が必要です。
メソッド (method)
メソッドとは、クラスの中で定義される、オブジェクトの振る舞い (操作・処理) を表すものです。プログラミング内では機能 (function) といわれることもあります。
インスタンス (Instance)
インスタンスとは、クラスという「設計図」をもとに、コンピュータのメモリ上に実体化されたモノ(オブジェクト)のことです。クラスはとても抽象的なもの。その抽象的に定義されたクラスから、具体的なオブジェクトが生成されます。その生成をインスタンスといいます。たとえば、インスタンスとは上記図の扇風機クラスから特定の Sabay Fan という扇風機オブジェクトを作ることです。
インターフェース (Interface)
オブジェクト指向におけるインターフェースとは、具体的な処理(中身)を書かずに、「メソッドの名前、引数、戻り値の型」というルール(契約)だけを定義したものです。自分で中身を持たないため、インターフェース単体では new してインスタンス化することはできません。他のクラスに implements (実装) してもらうことで、初めて命が吹き込まれます。
| インターフェース (仕様書 / 規格) |
「何ができるべきか (機能の約束)」を決めるもの |
| クラス (設計書) |
「それをどうやって実現するか (具体的な中身)」を書き込むもの |
なぜインターフェースがあるのか?
インターフェースはプログラムを部品化するために使います。 たとえば、もしインターフェースを使わず、特定のクラスにべったり依存したコードを書くとします。後からその部品を別のものに取り替えたいとなったときに、システム全体を巻き込む大改造が必要になってしまいます。インターフェースという「共通の規格(窓口)」を1つ挟むことで、中身の部品が何であれ、呼び出し側は同じ方法で利用できるようになります。(具体例は以下のポリモーフィズムを参照してください)
ポリモーフィズム (Polymorphism)
ポリモーフィズムとは、「同じ名前のメソッドを呼び出しているのに、中身のオブジェクトによって、全く異なる動きをする性質」のことです。「親(インターフェース)の型」の変数には、そのルールをクリアした「子(実装クラス)のインスタンス」なら何でも代入できる、というJavaの性質を利用して実現します。
- インターフェース作成
- インターフェースからクラスを実装
- 変数の型をインターフェースの型にして、処理を実装
具体例として、「通知(Notification)を送るシステム」を作ってみましょう。将来的に、通知方法を「メール」や「LINE」に切り替えられるように、インターフェースを使って設計します。まず、以下のようにインターフェースを作成します。見ての通り中身は空っぽです。
public interface NotificationService {
// 「通知を送る」という名前とルールだけを決める
void sendNotification(String message);
}次に、以下のようにルールに従った具体的な部品(クラス)を2つ作ります。
// メール通知の部品
public class EmailNotificationServiceImpl implements NotificationService {
@Override
public void sendNotification(String message) {
System.out.println("【メール送信】" + message);
}
}
// LINE通知の部品
public class LineNotificationServiceImpl implements NotificationService {
@Override
public void sendNotification(String message) {
System.out.println("【LINE送信】" + message);
}
}変数の型をインターフェースの型にします。(具体的なクラス名ではない)
- × EmailNotificationServiceImpl ※ 具体的なクラス名
- × LineNotificationServiceImpl ※ 具体的なクラス名
- 〇 NotificationService ※ インターフェース
以下の Main クラスから見ると service.sendNotification(…) という呼び出し側のコードは1文字も変わっていないのに、中身のインスタンスを差し替えるだけで、メールが飛んだりLINEが飛んだりと、挙動を自由に変えることができています。これがポリモーフィズムです。
public class Main {
public static void main(String[] args) {
// 親インターフェースの型に、子 (メール) の実体を代入する
NotificationService service = new EmailNotificationServiceImpl();
// 呼び出し方は「sendNotification」
service.sendNotification("システムが起動しました");
// 出力結果: 【メール送信】システムが起動しました
// ➔➔➔ ここで部品を「LINE」に差し替えてみます ➔➔➔
service = new LineNotificationServiceImpl();
// 呼び出し方は「全く同じ」なのに、動きが変わる!
service.sendNotification("システムが起動しました");
// 出力結果: 【LINE送信】システムが起動しました
}
}Spring Framework では、この new LineNotificationServiceImpl() というインスタンス化コードをなくすことが可能です。Spring での開発ではアノテーションを添えて変数を用意するだけでよくなります。(Spring については別途解説します)
Java 関連用語
Javaは、1995年にSun Microsystems (現Oracle社) によって開発されたオブジェクト指向のプログラミング言語です。大規模な基幹システムからWebアプリケーション、Androidアプリ、組み込みシステムまで、「強固で揺るがないインフラ」が必要な場面で圧倒的なシェアを誇っています。決済システムや会員管理、数百万人が使うWebサービスの裏側など、「バグによる停止が許されない」「何年にもわたって複数人でメンテナンスしていく」というタスクにおいて、Java は有効な選択肢になります。
主要な言語との位置づけの違いを、実行速度と開発効率の軸で比較すると以下のようになります。
| 言語 | 実行速度 | 開発効率・コードの柔軟性 | 主な用途 |
| Java | 高速 (JITコンパイラによる最適化) |
堅牢 (静的型付け、厳格な規約) |
基幹システム、Web、Android |
| C / C++ | 最高速 (ハードウェア直結) |
低い (メモリ管理などが手動) |
OS、ゲーム、組み込み |
| Python | 低速 (インタプリタ実行) |
最高 (簡潔で書きやすい) |
AI、データ分析、スクリプト |
| JavaScript | 中速 | 高い (動的型付け、非同期が得意) |
Webフロントエンド、サーバーサイド |
Java の長所
| 圧倒的な堅牢性と安全設計 | Javaは「コンパイル言語」であり、「静的型付け言語」です。プログラムを実行する前に、データ型の矛盾や記述ミスを厳しくチェックするため、バグが本番環境で発覚するリスクを大幅に減らせます。また、メモリ管理を「ガベージコレクション」という機能が自動で行ってくれるため、メモリリークによるシステムダウンが起きにくい設計になっています。 |
| 充実したエコシステムとフレームワーク | 世界中で長年使われているため、再利用可能なライブラリが膨大に存在します。特に、企業のWebアプリケーション開発では 「Spring Boot」 というデファクトスタンダードのフレームワークがあり、これを使うことで、認証やデータベース連携といった複雑なバックエンド処理を安全かつ強固に構築できます。 |
| 優れた後方互換性 | Javaは「古いバージョンで作ったプログラムが、新しいバージョンでもそのまま動くこと」を非常に重視しています。言語としての安定性が高く、企業が「一度作ったシステムを10年、20年と安心して運用できる」という大きな信頼に繋がっています。 |
| 進化を止めない言語仕様 | 保守的な一方で、近年は半年に一度のペースでアップデートが行われており、モダンな言語機能 (関数型プログラミングの要素、型推論、軽量スレッドである「Virtual Threads」など) が貪欲に取り入れられています。 |
Java の短所
| コードの記述量が多い | 安全性を重視する反面、他の言語に比べて「お決まりの定型コード (ボイラープレート)」が多くなりがちです。例えば、Pythonなら1行で書ける画面への出力も、Javaではクラスやメソッドの定義が必要になり、少量のコードをサクッと書いて動かすような「素早さ」を求める開発にはあまり向きません。 |
| 起動がやや遅く、メモリ消費量が大きめ | JVMという仮想マシンを起動してからプログラムを実行する特性上、起動時にどうしてもオーバーヘッドがかかります。そのため、数秒〜数ミリ秒で起動して消滅するようなサーバーレス (AWS Lambdaなど) の環境や、極限までメモリを節約したい小さな組み込みデバイスでは、C言語やGo、Rustといった言語の後塵を拝することがあります。 |
| オブジェクト指向の強制 | Javaは「すべてをクラスの中に書く」という純粋なオブジェクト指向の設計を強制されます。簡単なツールを1本作りたいだけでもオブジェクト指向の概念を理解して組み立てる必要があるため、初心者にとっての学習の壁が高くなりやすい側面があります。 |
Java仮想マシン (JVM)
Javaの本質を理解する上で最も重要なのがJVMという仕組みです。C言語などは、書いたコードをそのパソコンのOSが直接理解できる言葉に翻訳します。そのため、Windows用に作ったプログラムはそのままLinuxでは動きません。一方、Javaは一回「バイトコード」という共通のデータに変換され、OSの上で動く「JVM」がそれを読み取って実行します。この仕組みにより、「Write Once, Run Anywhere」という強力なクロスプラットフォーム性を実現しています。
よく使う基本用語集
| 変数 | variable | データを入れておく入れ物。変数を使うと、同じ値を何度も書かずに済み、コードが読みやすくなる。 |
| 値 |
value | 変数の中に入る具体的なデータ |
| 代入 |
assignment | 変数に値を入れること |
| 宣言 |
declaration | 変数を使う準備をすること |
| 初期化 |
initialization | 変数に最初の値を入れること |
型 (Data type)
型とは、データの種類とどんな操作ができるのかを分類するラベルのようなものです。
- 数値
- 文字列
- リスト
- etc.
Java プログラミング言語では、たとえば文字列を扱うには String という型を使います。Java では “” (ダブルクォーテーション) で囲まれた文字列を変数に格納します。この String を文字列型といいます。
String name = "Hanako";またよく使うのがリスト型です。たとえば List<String> という型は、String型のデータを、順番に並べて複数まとめて管理するデータの入れ物を指します。List というのは複数の変数をまとめて扱うことができるインターフェースのことです。List はサイズを変更できるのが特徴です。<String> というのはジェネリクス(Generics: 汎用型) と呼ばれる機能です。「リストに入るのは String 型だけです」ということをコンピューターに宣言するものになっています。
List<String> userList = new ArrayList();
userList.add("Hanako");
userList.add("John");型は2つあります。
- 基本データ型
- 参照型
基本データ型
基本データ型とはこれ以上分解できない、Javaが最初から用意している最も基本的な型です。変数の中に「値そのもの」が直接入ります。int, double, boolean などが該当し、小文字から始まるのが特徴です。
| int | 整数 (Integer) |
| double | 小数 (Floating-point number) |
| boolean | 真偽値 (true or false) |
int age = 35;コンピューターのメモリを引き出しで例えます。基本データ型は引き出しの中に、「値そのもの」が直接コロンと入っています。上記だと age という名前の引き出しを開けると、中にダイレクトに 35 という数字が入っています。
参照型
参照型とは「データがメモリ上のどこにあるかという住所(参照・ポインタ:Reference / Pointer)」が入るものです。String や List、クラスから作ったインスタンスなどはすべて参照型になります。変数の中にデータそのものが入らないことに注意が必要です。参照型は大文字から始まります。
String name = "Alice";こちらもメモリを引き出しで例えます。参照型はデータが大きくなる可能性があります。そのため、引き出しの中に直接データを入れることができません。データ本体は別の広い場所 (ヒープ領域: Heap memory) に置きます。引き出しの中には「その場所がどこかを示すメモ (住所)」だけを入れます。これがポインタ(参照)です。
name という引き出しを開けると、入っているのは「104号室」という住所が書かれたメモ (ポインタ) です。コンピュータはその紙を見て、104号室まで本物のデータを取りに行きます。 “Alice” という文字が引き出しに入っているわけではありません。
なぜポインタが必要なのか?
メモリを効率よく使い、プログラムの動作を速くしたいからです。
たとえば、大量のデータが入った List<String> (数千人分の顧客データなど) を、別のメソッドに引き渡して処理したいとします。もしポインタがなかったら、メソッドにデータを渡すたびに、数千人分のデータを丸ごとコピーして新しい引き出しを作らなければなりません。また、メモリはすぐにいっぱいになり、動作も重くなってしまいます。しかし、ポインタがあれば「データはそこ(104号室)にあるから、これ読んでおいてね」と、住所のメモを1枚渡すだけで済みます。どれだけ巨大なデータであっても、住所を教えるだけなら一瞬で終わるため、非常に効率的です。
引き出しの中のメモが「白紙(どこも指していない)」の状態のことを Null といいます。白紙の場合、コンピューターがどこにいったらよいかわからず NullPointerException を出します。
キャスト・型変換 (Cast / Type casting)
キャストとはその型として扱うための変換のことです。型変換と表現することもあります。あるデータ型を別のデータ型に強制的に変換します。
- 基本データ型のキャスト
- 参照型のキャスト
Javaは型に非常に厳しい言語です。キャストの仕組みを正しく理解していないと、思わぬバグやコンパイルエラーに直面することになるでしょう。
基本データ型 (プリミティブ型) のキャスト
数値の種類 (intやdoubleなど) を変換するパターンです。これには「自動」で行われるものと「強制」で行うものの2パターンあります。
int 型から double 型など扱える数字の範囲が広い型へキャストするときは、データが壊れる心配がないため、Javaが自動的に変換してくれます。大きな型から小さな型へキャストするときは、データが溢れて消えてしまう危険があるため、開発者が「リスクを承知の上で変換します」と明示的に指示する必要があります。その場合は括弧 () を使って指定します。
int num = 100;
double dNum = num; // intからdoubleへ自動変換される (100.0 になる)double dNum = 123.45;
int num = (int) dNum; // 小数点以下が切り捨てられ、123 になる (情報が欠落)参照型 (オブジェクト) のキャスト
オブジェクト指向のクラス構造 (親子関係) の間で型を変換するパターンです。実務としてはこちらを主に使用します。
- アップキャスト (Upcasting)
- ダウンキャスト (Downcasting)
アップキャスト
子クラス (詳細なクラス) のインスタンスを、親クラス (大まかなクラス) の型に変換することです。これは常に安全なので、キャスト記号を使わず自動で行えます。
// Car クラスを継承した Prius クラスがあるとします
Prius myPrius = new Prius();
Car myCar = myPrius; // アップキャスト (自動)ダウンキャスト
親クラスの型として扱われているオブジェクトを、元の子クラスの型に格下げ (復元) する操作です。これは失敗するとアプリがクラッシュする危険があるため、明示的なキャスト () が必須です。
Car myCar = new Prius(); // 中身はプリウスだけど、扱いは普通の車
Prius myPrius = (Prius) myCar; // ダウンキャスト (明示的)ダウンキャストには ClassCastException の危険が伴います。たとえば以下のコードだとその例外が発生します。中身が「BMW」である変数を、間違えて「Prius」にダウンキャストしようとすると、プログラムは実行中に例外を発生します。
Car myCar = new Bmw(); // 中身はBMW
Prius myPrius = (Prius) myCar; // ❌ 実行時に ClassCastException ClassCastException を回避するには、instanceof のパターンマッチング を使うとよいでしょう。以下のような if文で、安全性の確認とキャストの記述を安全に1行にまとめることができます。
Object obj = "Hello";
// objの中身がString型であるかチェックし、そうなら自動で変数「str」にキャストする
if (obj instanceof String str) {
System.out.println(str.toUpperCase()); // 安全にStringとして使える
}間違った参照型のキャストは ClassCastException を引き起こすため、 instanceof のパターンマッチングで例外を回避しつつ、キャストしましょう。
基本構文
| 構文名 | 英語表記 | 定義・役割 | 構文イメージ |
| for文 | for loop | カウンター変数を使い、指定した回数だけ処理を正確に繰り返す構文。 | for (初期化; 条件式; 更新) { 処理 } |
| 拡張for文 | enhanced for loop | 配列やリストの全要素を、最初から最後まですべて自動的に1つずつ取り出して繰り返す構文。 | for (型 変数 : コレクション) { 処理 } |
| while文 | while loop | 条件式が true である間、処理を何度も繰り返す構文。回数が決まっていないループに最適。 | while (条件式) { 処理 } |
| if文 | if statement | 条件式の評価結果 (true / false) に応じて、処理を分岐させる構文。 | if (条件式) { 処理 } |
| switch文 / 式 | switch statement switch expression |
一つの変数や式の値に応じて、多数の選択肢から一致する処理を実行する構文。 | switch (変数) { case 値 -> 処理; } |
for文・拡張for文
for文とは処理を正確に何度も繰り返す構文のことです。構文としては以下の2つがあります。
- for文
- 拡張for文
for 文
for文はカウンター変数を使い、指定した回数だけ処理を正確に繰り返す構文のことです。何回ループを回すか、インデックス (i) を細かく管理する必要があります。構文イメージは for (初期化; 条件式; 更新) { 処理 } の形です。i が存在しないインデックスにアクセスするエラー (IndexOutOfBoundsException) が起きる可能性があります。
List<String> list = Arrays.asList("Alice", "Bob", "Charlie");
// 従来:インデックスを管理する
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}拡張for文
拡張for文では、for文のループの制御を隠蔽して中身の処理だけを記述することができます。java5以降で使用可能です。拡張for文は以下のようなときに使うとよいでしょう。
- ループ処理の中で return を使ってメソッドを途中で抜け出したい
- break や continue を使って、ループの途中でスキップや中断を制御したい
- 処理が複数行に及び、ラムダ式の中に書くとコードがごちゃごちゃしてしまう
List<String> list = List.of("Alice", "Bob", "Charlie"); // List.ofはJava 9以降
// 拡張for文(読みやすい)
for (String name : list) {
System.out.println(name);
}foreach メソッド
foreach メソッドは構文ではなく、List などのオブジェクトが自身に持っているメソッドです。「ラムダ式 (Lambda expression)」 という処理そのものを引数として渡す書き方とセットで使用します。List などのデータに対して データ.forEach(変数名 -> 行いたい処理) と記述してください。このメソッドは以下の場合に使うとよいでしょう。
- 取り出したデータをただ画面に出力したり、別の場所へそのまま渡したりするだけのシンプルな1行処理
- Stream APIと組み合わせて、一連の流れの中でまとめて処理したい
List<String> list = List.of("Alice", "Bob", "Charlie"); // List.ofはJava 9以降
// Stream API(関数型プログラミング風)
list.forEach(name -> System.out.println(name));上記と全く同じ処理をメソッド参照を用いて以下のように書くこともできます。(メソッド参照に関して詳しくは後述)
// さらにシンプルな書き方 (メソッド参照)
frameworkList.forEach(System.out::println);while 文
while 文は、条件式が true である間、処理を何度も繰り返す構文です。回数が決まっていないループに最適。構文イメージは while (条件式) { 処理 } になります。
// while文の構文は昔も今も同じ
int count = 0;
while (count < 3) {
System.out.println(count);
count++;
}if文
if文は、条件式の評価結果 (true / false) に応じて、処理を分岐させる構文です。構文イメージは if (条件式) { 処理 } になります。
Java 16 以前は下のようにキャストをする必要がありました。
Object obj = "Hello Java";
// 従来:型をチェックしたあと、わざわざキャストする
if (obj instanceof String) {
String str = (String) obj; // このキャストが面倒
System.out.println(str.toUpperCase());
}Java 16 以降は、型チェックと同時に自動でキャストされた変数をその場で宣言できるようになりました
Object obj = "Hello Java";
// 最新:チェックと同時に変数宣言まで完了する
if (obj instanceof String str) {
// すでにString型の変数「str」として使える
System.out.println(str.toUpperCase());
}switch 文 / 式
switch 文 / 式は一つの変数や式の値に応じて、多数の選択肢から一致する処理を実行する構文です。構文イメージは switch (変数) { case 値 -> 処理; } になります。
以前は以下のように記述していました。この書き方だとbreak; を書き忘れると、下の処理まで勝手に実行されてしまう危険があります。また、値を返すために一度外側で変数(例: result)を用意して代入する必要がありました。
// 従来:行数が多く、breakの消し忘れが怖い
String day = "MONDAY";
String result = "";
switch (day) {
case "MONDAY":
result = "週の始まり";
break;
case "FRIDAY":
result = "週末";
break;
default:
result = "平日";
break;
}今は矢印記号 -> を使うことで、break; が不要になりました。switch文全体が値を返す式になったため、変数へ直接代入できます。
// 最新:スッキリ安全に書ける
String day = "MONDAY";
String result = switch (day) {
case "MONDAY" -> "週の始まり";
case "FRIDAY" -> "週末";
default -> "平日";
}; // 式なので最後にセミコロンが必要昔は今の書き方と違っていたことを頭の片隅に置いておくとよいでしょう。過去のソースを見るときに役立つかもしれません。
ラムダ式(Lambda Expression)
ラムダ式は、名前のない使い捨てのメソッドをその場で書くための構文です。下図が示す通り、ラムダ式は以下の3つのパーツを -> で繋いで構成します。

- 引数リスト: メソッドに渡される変数
- アロー記号: ->
- 処理本体: 実行したい具体的な処理
Javaのラムダ式は、コンパイラが周囲のコードから型を推測してくれるため、極限まで省略して書くことができます。
// 1. 基本形
(String name) -> {
System.out.println(name.toUpperCase());
};
// 2. 引数の「型」を省略 (Javaが自動でStringだと見抜いてくれます)
(name) -> {
System.out.println(name.toUpperCase());
};
// 3. 引数の括弧 () を省略 (引数が「1つだけ」のとき限定で外せます)
name -> {
System.out.println(name.toUpperCase());
};
// 4. 波括弧 {} を省略 (処理が「1行だけ」のとき限定で外せます)
name -> System.out.println(name.toUpperCase())メソッド参照 (Method Reference)
メソッド参照は、ラムダ式をさらに極限までシンプルにした書き方です。 :: (ダブルコロン) という記号を使います。ラムダ式の引数の記述すら省略して、呼び出したいメソッドの名前だけをスマートに指し示そうとしています。
| パターン | ラムダ式 | メソッド参照 | 説明 |
| インスタンスメソッドの呼び出し (特定のオブジェクトのメソッド) | name -> System.out.println(name) | System.out::println | 受け取った引数を、そのまま System.out.println() に渡すケースです。 |
| 引数自身のメソッドを呼び出す場合 | str -> str.toUpperCase() | String::toUpperCase | 受け取った引数 (String型など) が持っているメソッドを、その引数自身に対して実行するケースです。 |
| クラスメソッド (staticメソッド) の呼び出し | value -> Integer.parseInt(value) | Integer::parseInt | どこかのクラスが持っている共有の便利メソッドに、引数をそのまま放り込むケースです。 |
ラムダ式とメソッド参照をコードで比較
以下のコードで、実際の forEach 処理の中でどのように処理されているか見比べてください。「リストの各要素に対して、出力を実行する」という目的だけが1行で直感的に読めるようになっているのが分かります。
List<String> list = List.of("alice", "bob", "charlie");
// 1. 拡張for文
for (String name : list) {
System.out.println(name);
}
// 2. ラムダ式
list.forEach(name -> System.out.println(name));
// 3. メソッド参照
list.forEach(System.out::println);ラムダ式 (->) は、処理をその場にコンパクトに書き下ろすためのメソッドです。メソッド参照 (::) はラムダ式をさらに短縮してメソッド名だけで表現する技法になります。
StreamAPI
StreamAPI は配列やリストなどのデータの集まりに対して、フィルターをかけたり、形を変換したり、合計を計算したりする一連の処理を、流れるような一本のパイプラインのように記述できる仕組みです。これを使うことで、以前説明した for 文や if 文を大量にネスト (入れ子) にした複雑なコードを、驚くほどスッキリと、読みやすく書き換えることができます。Stream APIで行う処理は、必ず以下の3つのステージ (段階) を順番に通り、一本のパイプラインを形成します。
- ストリームの生成
- 中間操作
- 終端操作
| ストリームの生成 | 元のデータ (Listや配列など) を、Stream API専用の通り道 (ストリーム) に流し込みます。 | list.stream() |
| 中間操作 | 流れてきたデータに対して、「加工」や「絞り込み」を行います。中間操作の最大の特徴は、結果もまたストリームのまま返ってくるため、何個でも数珠繋ぎ (チェイン) にできる点です。 | filter() (条件に合うものだけに絞り込む) map() (データを別の形に変形する) |
| 終端操作 | 加工が終わったデータを、最終的な結果 (新しいList、1つの数値、画面への出力など) として、ストリームの外へ取り出す処理です。終端操作を行うと、そのストリームは閉じられます。 | toList() (新しいリストにまとめる) count() (件数を数える) foreach() (1つずつ処理する) |
StreamAPIを使わない場合と使う場合を比較する
StreamAPIを使わない場合、データの入れ物 (空のリスト) を手動で用意し、ループを回しながら条件判定をして、手作業で詰め込む必要があります。
// StreamAPIを使わない場合、どのように処理するかを細かく命令する
List<String> resultList = new ArrayList<>();
for (User user : userList) {
if (user.getAge() >= 20) { // 1. 20歳以上で絞り込み
String upperName = user.getName().toUpperCase(); // 2. 大文字に変換
resultList.add(upperName); // 3. リストに追加
}
}Stream APIを使った場合、「何をしたいか」を順番に宣言していくスタイル (宣言型プログラミング) に変わり、前述したラムダ式やメソッド参照と組み合わせると以下のようになります。
// StreamAPIを使った場合、流れるようなパイプラインで記述する
List<String> resultList = userList.stream()
.filter(user -> user.getAge() >= 20) // 1. 中間操作: 絞り込み
.map(user -> user.getName().toUpperCase()) // 2. 中間操作: 変換
.toList(); // 3. 終端操作: 新しいリストにまとめるWebアプリケーションのビジネスロジック (データの処理部分) では、このStream APIを使ってコードを書くので身につけておきましょう。
アノテーション (Annotation)
例外処理
Javaにおける「例外 (Exception)」とは、プログラムの実行中に発生する「想定外のエラー」のことです。例外は、以下のようなものを指します。もし例外を何も処理せずに放置すると、プログラムはその時点で強制終了・クラッシュしてしまいます。
- 存在しないファイルを開こうとする
- ネットワークが切断される
- データベースへの接続に失敗
例外によるプログラムの強制終了を防ぎ、安全にシステムを動かし続けるための仕組みが例外処理です。Java では以下のように try – catch – finally で記述するのが基本です。
try {
// ① 例外が発生するかもしれない処理(通常ルート)
System.out.println("ファイルを読み込みます...");
} catch (IOException e) {
// ② ①で特定の例外(例: ファイルが見つからないなど)が発生した場合だけ実行される処理(迂回ルート)
System.out.println("エラーが発生しました: " + e.getMessage());
} finally {
// ③ 例外が起きても起きなくても、「最後に必ず実行される」処理(後片付け)
System.out.println("ファイルの後片付け(クローズ)を行います。");
}例外は2種類ある
[Throwable]
|
+-----------+-----------+
| |
[Error] [Exception]
(回復不能なエラー) |
+-------------------+-------------------+
| |
[チェック例外] [非チェック例外]
(IOException, SQLExceptionなど) (RuntimeException)
|
(NullPointerExceptionなど)| Error | メモリ不足など、アプリ側では復旧不可能な重度の障害 |
| Exception | 例外。開発者は主にこちらに対処する。 |
| チェック例外 (Checked Exception) |
コンパイル時にJavaから対策を強制される例外。try-catchなどで対策する。対応しないとコンパイルできない。 |
| 非チェック例外 (Unchecked Exception) |
コンパイル時に対策を強制されない例外。いわゆる RuntimeException のこと。こちらは NullPointerException が出ないような記述をするなど、try-catch よりは記述で対応する。 |
Spring Framework では、SQLExceptionなどを try-catch でエラーハンドリングしなくて済むようになっています。Springは、裏側で発生した面倒なチェック例外をすべて自動的に「Spring独自の非チェック例外(RuntimeExceptionの仲間)」に変換して投げ直してくれる仕組みがあります。(Spring については別途解説します)
プログラミング開発
Java SE と Jakarta EE
Java には大きく Java SE と Jakarta EE があります。歴史の変遷を経て、現代のJavaを支えるものです。これらは現在、完全に役割が分担されており、「Java SEという土台 (言語仕様) の上に、Jakarta EEというWeb用の規格 (パーツ群) が載っかる」というレイヤー構造になっています。
| Java SE | プログラミング言語としての基本機能 | 旧J2SE |
| Jakarta EE | Webサーバーや企業向けシステムを作るための追加機能の仕様書 | 旧J2EE / Java EE |
Java SE
Java SEは、Oracleを中心としたコミュニティ (JCP: Java Community Process) が開発を主導している、すべての中心となるプラットフォームです。中身は主に以下の通りです。
- var (ローカル変数型推論) や record、新しい switch 構文などの言語の文法。
- List や Map などのコレクションフレームワーク。
- Stream APIやラムダ式、マルチスレッド処理などの基本機能。
- Javaを実行するためのエンジンである JVM (Java仮想マシン)
Jakarta EE
大規模Web開発のための「共通ルールの集合体」です。Java SEが「プログラミング言語としての基本機能」を提供しています。それに対し、Jakarta EEは「Webサーバーや企業向けシステムを作るための追加機能の仕様書」を集めたものです。最大の特徴として、仕様(ルール)であり実体(製品)ではないため、Jakarta EE はインターフェースの集まりでしかありません。中身の具体的なプログラムは、世界中の様々な企業や団体が「Jakarta EEのルール通りに作りました」として製品化しています。
Jakarta EE に含まれるAPI
| Jakarta Servlet | WebブラウザからのHTTPリクエストを受け取り、レスポンスを返すためのWeb通信のルール |
| Jakarta Persistence (JPA) | Javaのオブジェクトを、リレーショナルデータベース(RDB)のテーブルに自動で綺麗にマッピング(紐付け)して保存するSQL操作の共通ルール |
| Jakarta Validation | 変数に @NotNull などのアノテーションをつけて、「値が空っぽであってはならない」といった入力チェックを行うための共通ルール。 |
Spring Boot

Spring Boot とは、Spring Frameworkに含まれるフレームワークの1つになります。フレームワークは開発を簡単にする仕組みのことです。Spring Boot でのアプリケーションは、上記の階層で動くことになります。Spring Bootは Jakarta EEの規格・Jakarta EE に含まれるAPIを裏側で採用しています。Spring について詳しくは、以下のリンクから別記事をご参照ください。
パッケージ (Package)
パッケージとは、クラスをまとめて入れておくディレクトリのような仕組みです。Java での開発では、機能ごとにクラスファイルをまとめておきます。プログラムの規模が大きくなればなるほどクラスが増えてしまうため、それをまとめるために使用します。同じクラス名でもパッケージが違えば別のものとして扱えたり、パッケージに対し「このクラスからしか見えないようにする」というようなアクセス制御を行えたりするのが特徴です。Java クラスを分類しておくことで、クラスを探しやすくし、アクセス制御として使うこともできます。
| パッケージ1 | database 処理を行うクラス群 (database) |
| パッケージ2 | 便利なクラス群 (util) |
| パッケージ3 | ログ関連のクラス群 (log) |
Java クラスは必ずパッケージに所属することになります。Java でのプログラミング開発では、Java クラスがどのパッケージに属するかも考慮しなければなりません。
JARファイル (Java Archive File)
一言でいうと「Javaのプログラムに必要なファイルを一つにまとめた、特製のZIPファイル」です。Javaのプログラムは、コンパイルするとたくさんの .class ファイルに分かれます。さらに、画像などの画像素材(リソース)や外部のライブラリも必要になります。これらをバラバラのまま持ち運ぶのは大変なので、1つのファイル (.jar) にパッケージング (Packaging) するのがJARファイルの役割です。
JARファイルのメリット
| 持ち運びが簡単 (Portability / Distribution) |
何百個もあるファイルを1ファイルにまとめられるため、配布 (ディストリビューション) やサーバーへのデプロイ(配置)が圧倒的に楽になります。 |
| ファイルサイズを削減 (Compression) |
ZIP形式で圧縮されているため、データサイズが小さくなり、ディスク容量や通信帯域を節約できます。 |
| そのまま実行できる (Executable) |
設定次第で、ダブルクリックするかコマンドを1行打つだけでプログラムを起動できるようになります。 |
JARファイルは、その使われ方によって大きく2つの役割に分かれます。
- 実行可能JAR (Executable JAR) ・・・アプリとして動かす
- ライブラリJAR (Library JAR)・・・部品として使う
実行可能JAR
実行可能JARは、それ単体でアプリケーションとして起動できるJARファイルです。 中に「最初に実行するクラス(main メソッドを持つクラス)」がどこにあるかの情報が記録されており、以下のようなコマンドで簡単に実行できます。
java -jar myapp.jar| Entry point | プログラムが開始される場所、Javaではmainメソッドのこと |
| Manifest file (META-INF/MANIFEST.MF) |
JARファイルの中身の「目次」や「設定情報」が書かれたテキストファイル。ここにエントリーポイントが記録されます |
ライブラリJAR
ライブラリJARは、他のプログラムから「部品」として呼び出して使うためのJARファイルです。Java では、あらかじめ便利な機能を持つクラスが多数用意されています。その機能がまとまったものをライブラリと呼びます。Jackson なども、JARの形で配られています。自分のプログラムにライブラリJARファイルを組み込む (読み込ませる) ことで、その中にある便利なクラス群を自由に使えるようになります。
| Dependency | 依存関係のこと。自分のプログラムが動くために、他のライブラリJARを必要としている状態 |
| Classpath | Javaがプログラムを実行する際に、「必要なJARファイルやクラスファイルがどこにあるか」を探すための検索経路 |
そのほか (Fat JAR / Uber JAR)
これらとは別に、Fat JAR / Uber JARというJARファイルもあります。これは自分の作ったプログラムだけでなく、依存している外部のライブラリJAR (Jacksonなど) もすべて中に丸ごと詰め込んだ、特大のJARファイルのことです。これ1つあれば本当にどこでも動くため、Spring Bootなどではこの形式がよく使われています。
JARファイルは、開発したシステムを本番環境に公開するときには必ず触ることになります。
JSON
JSON (ジェイソン) とは、「JavaScript Object Notation」の略で、システム間でデータをやり取りするための、軽くて読みやすいテキストフォーマットのことです。略語に JavaScript が入っていますが、JavaScript 専用というわけではありません。Java、Python、C#、PHPなど、現在あらゆるプログラミング言語やシステム間でデータをやり取りする際の世界標準 (Global standard) として使われています。JSONが登場する前は「XML」がよく使われていましたが、現在のWeb開発ではJSONが主流です。Java開発では、Webから届いたJSONをJacksonなどを使ってJavaオブジェクト(インスタンス)にパースして処理を行います。
JSONは、基本的に「キー (Key)」と「値 (Value)」のペア (Key-Value pair) をコロン : で繋ぎ、全体を波括弧 {} で囲んで表現します。
{
"name": "山田太郎",
"age": 30,
"isEmployee": true,
"skills": ["Java", "SQL", "Git"],
"address": {
"city": "東京都",
"zipcode": "100-0001"
}
}JSONを使うメリット
| Human-readable | 構造がシンプルで、パッと見でどんなデータなのか人間が簡単に理解できます。 |
| Lightweight | 余計な文字が少なくデータサイズが小さいため、ネットワーク通信の速度を速くできます |
| Language-independent | ほぼすべてのプログラミング言語が、JSONを自分の言語のオブジェクト・Javaインスタンスに変換する標準機能やライブラリを持っています。 |
JSONで扱えるデータ型
| 文字列 (String) | 必ずダブルクォーテーション “” で囲みます。 |
| 数値 (Number) | 整数や小数をそのまま書きます。 |
| 真偽値 (Boolean) | true または false |
| ヌル (Null) | 値が空っぽであることを示す null |
| 配列 (Array) | 角括弧 [] を使い、複数のデータを順番に並べます。Javaの List に相当します。 |
| オブジェクト (Object) | 波括弧 {} を使い、さらにその中にキーと値のペアをネスト(入れ子)にできます。(上記JSON例の address 箇所) |
関連用語
| Parse | ただの文字列であるJSONを分解して、プログラムが扱えるオブジェクトに翻訳・変換する処理のことです。(デシリアライズとほぼ同義で使われます) |
| JSON Payload | ネットワーク通信 (HTTPリクエスト/レスポンス) のボディに含まれる、実際のJSONデータそのもののことです。 |
| JSON Schema | JSONデータの構造やルールの「定義書・バリデーションルール」のことです。たとえば「このJSONには必ず name というキー(文字列)を含めなければならない」というようなもの |
JSONとは、データを表現するための形式のことです。システム間でデータをやり取りするために使用します。 “キー”: 値 の組み合わせで表現可能です。
Jackson ライブラリ
JacksonライブラリはJava開発におけるデータのやり取りで使用するものです。特にWeb API (REST API) の開発で欠かせません。Jacksonは、JavaのオブジェクトとJSONというデータ形式を、相互に変換するための世界標準的なライブラリです。SpringBootなどの主要なフレームワークにも標準で組み込まれています。Jacksonの主な役割は、Javaのプログラムが理解できるオブジェクトと、ネットワークやファイルで扱いやすいJSON文字列の間を翻訳することです。
| シリアライズ / 直列化 Serialization / Marshalling | JavaオブジェクトをJSON文字列に変換する処理のことです。 |
| デシリアライズ / 逆直列化 Deserialization / Unmarshalling | 外から受け取ったJSON文字列を、Javaオブジェクトに復元する処理のことです。 |
Java オブジェクトと JSON の変換イメージ
たとえば、以下のような User クラス (Javaのオブジェクト) があるとしましょう。シリアライズ/デシリアライズするには ObjectMapper クラスを使用します。
public class User {
public String name;
public int age;
}これをシリアライズすると、以下のようになります。(Javaオブジェクト→JSON)
ObjectMapper mapper = new ObjectMapper();
User user = new User();
user.name = "Alice";
user.age = 25;
// JavaオブジェクトをJSON文字列に変換 (Serialize)
String jsonString = mapper.writeValueAsString(user);
System.out.println(jsonString);
// 出力結果: {"name":"Alice","age":25}また、デシリアライズするには以下のようにします。(JSON→Javaオブジェクト)
String jsonInput = "{\"name\":\"Bob\",\"age\":30}";
// JSON文字列をUserクラスのインスタンスに変換 (Deserialize)
User user = mapper.readValue(jsonInput, User.class);
System.out.println(user.name); // 出力結果: BobJackson はJavaとJSONをつなぐライブラリ。開発現場では ObjectMapper クラスでシリアライズ/デシリアライズして使用します。
Lombok (ロンボック)
Lombok (ロンボック) は、アノテーションの恩恵を活かしたライブラリです。このライブラリは、Java特有の退屈で大量の決まりきったコード (ボイラープレートコード) をアノテーションを数行書くだけで自動生成します。クラスの「ゲッター/セッター」や「コンストラクタ」をコード上に一切書かなくても、アノテーション1つでよくなります。このライブラリを用いることで、ソースコードを劇的にスッキリさせることができます。
Lombokを使わない場合
public class User {
private String name;
private int age;
// コンストラクタ (初期化のための特殊なメソッド)
public User(String name, int age) {
this.name = name;
this.age = age;
}
// ゲッター (値を取得するメソッド)
public String getName() { return name; }
// セッター (値をセットするメソッド)
public void setName(String name) { this.name = name; }
public int getAge() { return age; }
public void setAge(int age) { this.age = age; }
// (この後さらに toString() メソッドなども手書きするとさらに伸びる...)
}Lombok を使わないと上記のようにゲッター、セッターなどを記述する必要があります。
Lombokを使う場合
import lombok.Data;
import lombok.AllArgsConstructor;
@Data // これでゲッター、セッター、toStringなどが全部自動生成!
@AllArgsConstructor // これで全属性を持ったコンストラクタが自動生成!
public class User {
private String name;
private int age;
}Lombokのアノテーションをクラスの上に記述するだけで、上記のコンストラクタ、ゲッター、セッターがすべて裏側で自動生成されます。コードの見た目はこれだけですが、他のクラスからは手書きしたときと全く同じように user.getName() や user.setAge(25) を呼び出すことができます。
よく使われるLombokの主要アノテーション
| @Getter / @Setter | その名の通り、ゲッターとセッターを自動生成します。クラス全体につけることも、特定の変数だけに単体でつけることもできます。 |
| @ToString | System.out.println(user) を実行したときに、中身のデータが綺麗に見える文字列 (例: User(name=Alice, age=25)) を出力してくれるメソッドを自動生成します。デバッグに超便利 |
| @Data | 超強力な詰め合わせパックです。@Getter, @Setter, @ToString など、よく使うアノテーションの機能を一発でまとめて適用してくれます。 |
| @NoArgsConstructor / @AllArgsConstructor | 「引数なしのコンストラクタ (No argument)」や、「すべての属性を引数に受け取るコンストラクタ (All arguments)」を自動生成します。 |
Lombok は、Javaコードを減らすライブラリ。@Data などのアノテーションをつけるだけで、裏側でコンパイラと協力してメソッドを自動生成してくれます。コードの行数が減るため、可読性があがります。
Lombok を使うには?
Lombok を使うには Maven などのビルドツールの設定ファイルに記述を加える必要があります。以下は Maven の設定ファイル pom.xml の記述例です。Lombok を導入するときの参考にしてください。(ビルドツールについて詳しくは後述)
<dependencies>
<!-- 他のライブラリの記述がここに並びます -->
<!-- Lombokの依存関係を追加 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.30</version>
<scope>provided</scope>
</dependency>
</dependencies><!-- Spring Bootプロジェクトの場合の書き方 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<!-- バージョンはSpring Bootが最適なものを自動選択してくれるため不要 -->
<scope>provided</scope>
</dependency>Lombokの設定で最も特徴的なのが、この provided (プロバイディド) というスコープ指定です。これは、「このライブラリは、コンパイル (ビルド) するときだけ使用し、最終的に成果物 (JARファイルなど) として出荷するときには含めないでください」 というMavenへの指示になります。
Lombokの役割は、コンパイルの瞬間に裏側でゲッターやセッターのコードを自動生成することです。コンパイルが終わってしまえば、生成されたメソッド自体はすでにクラスファイルの中にしっかりと組み込まれているため、Lombokというライブラリ自体は実行時には不要になります。そのため、無駄なファイルサイズを増やさないよう、この provided を指定するのが決まりとなっています。
この設定を pom.xml に保存すると、Mavenがインターネット上のセントラルリポジトリ (公式のライブラリ倉庫) から、LombokのJARファイルを自動的にパソコンへダウンロードしてくれます。これにより、前回記述したような @Data などのアノテーションがコード内で認識できるようになり、ビルド時に自動生成されるようになります。
バージョン管理ツール
ビルドツール
HTTPリクエストとレスポンス
Javaで開発作業をするなら、ブラウザとサーバーの間で行われるHTTPという共通の通信ルールもおさえておきましょう。Webでの通信は「リクエスト」と「レスポンス」の1往復で完結します。サーバー側は、リクエストが来ない限り勝手にデータを送ることはできません。必ず「リクエストを受け取って、レスポンスを返す」という受動的な動きになります。
- クライアント (ブラウザ, スマホアプリなど)
- サーバー (Spring Boot など)
HTTPリクエスト
クライアントからサーバーに送られてくるリクエストの中には、主に以下の情報が含まれています。「何をお願いしているか?」という情報です。
| HTTPメソッド (HTTP Methods) |
「そのデータに対して、何をしたいか」というアクションの目的を表します。たくさんの種類がありますが、実務で使う基本は以下の4つです。 ・GET: データを「取得」したいとき(例: 画面を表示する、商品一覧を見る) ・POST: 新しいデータを「登録・送信」したいとき (例: 会員登録ボタンを押す、ブログを投稿する) ・PUT / PATCH: 既存のデータを「更新」したいとき。 ・DELETE : データを「削除」したいとき |
| パス / URL (Path / URI) |
「サーバー内の、どの機能(画面)を呼び出したいか」という目的地の住所。 例: /products (商品一覧ページ)、/users/123 (ID 123のユーザー詳細ページ) |
| リクエストボディ (Request Body) | POST や PUT のときに、画面のフォームに入力された文字や、送信したいデータ本体 (JSONなど) が詰め込まれる隠れた段ボール箱のような領域です。GET のときは原則として空っぽです。 |
HTTPレスポンス
サーバー (Spring Bootなど) が処理を終え、ブラウザに返す返事の中身です。
| ステータスコード (HTTP Status Codes) |
処理の結果がどうなったかを、3桁の数字で表す世界共通のものになります。以下はその一部です。 ・200 OK: 大成功。リクエストされたデータを正しく返します。 ・400 Bad Request: クライアント側の入力エラー (例: 必須項目が空っぽ、数字の場所に文字が入っている) ・404 Not Found: 指定されたURLが存在しない、または探しているデータが見つからない ・500 Internal Server Error: サーバー側のプログラム (Javaコード) の中で、先ほど登場した例外などが発生してクラッシュした |
| レスポンスボディ (Response Body) |
ブラウザの画面に表示するための HTML や、モダンなフロントエンド (Vue.jsやReact、スマホアプリ) に引き渡すための生データであるJSONなど、成果物そのものがここに入ります。 |
Spring Bootを使ってWebアプリ (コントローラー) を書くとき、開発者はこのHTTPのルールをそのままアノテーションとしてマッピング (紐付け) していきます。
@RestController // 「このクラスはWebの窓口(HTTPレスポンスを返す役割)ですよ」という目印
public class ProductController {
// ブラウザから「GET /products」というリクエストが来たら、このメソッドを動かす
@GetMapping("/products")
public List<String> getProductList() {
// Javaの不変リスト(Java 9以降の機能)を使ってデータを返す
// Springがこれを自動的に「JSON形式」のレスポンスボディに変換して、ステータスコード 200 OK で返します
return List.of("珈琲豆", "マグカップ", "エスプレッソマシン");
}
}アノテーションである @GetMapping(“/products”) を貼るだけで、「HTTPメソッドが GET で、パスが /products のリクエストをこのメソッドに流し込む」というWebのルーティングが完了します。Javaのコード側では、HTTPの難しい通信規格を意識することはありません。普通のメソッド (getProductList) としてビジネスロジックに集中できるのが、Spring Bootの圧倒的に便利なところです。
Git
Git とはファイルの変更履歴を記録するバージョン管理システムです。自分のパソコン (ローカル) の中で動きます。
GitHub
GitHub とは世界中の開発者がプログラムのソースコードを預け、チームで共有し、みんなで協力して開発を進めるための世界最大のWebプラットフォームです。Gitで記録した履歴やソースコードを、ネット上のサーバーにアップロードして、みんなで共有・管理できるようにしたWebサービスになります。
基本ワークフロー
[Main(本番コード)] ──┬─────────────────────────────┬──>(安全に維持)
│ ▲
▼ [枝分かれ(Branch)] │
└─> [自分の作業スペース] ───[Pull Request(レビュー要求)]現在の現場では、1つのプログラムを複数人で同時に、安全に開発するために以上のような流れをとります。これらは毎日何度も繰り返される基本動作です。基本的な流れについて詳しくは以下をご確認ください。
| Branch (ブランチ) |
本番環境で動いている綺麗なソースコード (Main) を汚さないよう、そこから自分の作業用に「コードのコピー(枝)」を作成します。これをブランチと呼びます。開発者はこの自分だけの安全なパラレルワールドの中で、自由にコードを書き換えます。 |
| Pull Request (プルリクエスト) |
バグ修正や新機能の追加が終わったら、GitHub上でチームのメンバーに対して、「私の書いたこのコードに問題がなければ、本番のコード(Main) に合流 (マージ) させてください!」とボタン一つで申請を送ります。実務ではこれを略して「プルリク」や「PR」と呼びます。 |
| Code Review (コードレビュー) |
プルリクエストのあと、開発メンバーはコードレビューをし、GitHubの画面上で修正前と修正後のコードの差分 (違い) を1行ずつ見比べます。 「このJavaのコード、NullPointerException が出るリスクがあるから直して」「Stream APIを使ってこう書いた方がいい」 このようなコメントをコードのその行に直接ピン留めしてチャット形式で議論します。 |
| Approve (承認) |
コードレビューを経て、レビュー担当者が承認することで、初めてコードが本番に合流(マージ)されます。 |
GitHub の機能
| GitHub Actions (CI/CDの自動化) |
開発者がプルリクエストを送ったり、コードを合流させたりした瞬間、GitHub側のサーバーが裏側で自動的に動き出し、Mavenのビルドテストを勝手に実行してくれます。 もしコードに不備があってコンパイルエラーになったり、テストが落ちたりすると、GitHubが「テストが失敗しました!このコードは合流させられません!」と自動でブロックしてくれます。人間の目だけでなく、システムが自動で品質を守る仕組みです。 |
| Issue (課題管理) |
「〇〇のバグを直す」「商品一覧画面を作る」といったタスクをGitHub上でチケット化し、誰が今どの作業を担当しているかをカンバン方式 (タスクカードを動かす画面) で視覚的に管理します。 |
Docker
Docker とは自分のパソコンの中に、本番環境と全く同じ構成のサーバー(仮想環境)を一瞬でかつ軽量に立ち上げられる仕組みです。「自分のPCでは動くのに、サーバーに持っていくと動かない」という環境依存の問題を、アプリケーションを実行環境 (JavaやOSの仕組み) ごとコンテナにパッケージングすることで完全に解消します。
| Docker | コンテナ技術は、ホストのOSの心臓部をうまく共有しながら、アプリの実行に必要な部分だけを隔離された空間として切り出す |
| VM (Virtual Machine) による仮想化 | Windowsの上に別のOSを丸ごと1つ起動する方式だったため、起動に数分かかり、パソコンのメモリも大量に消費する非常に重い |
Docker は従来のVMによる仮想化に代わるものです。OSの丸ごと起動が不要になり、わずか数秒で起動する超軽量な仮想環境が実現します。
Java 開発での Docker 利用
Java 開発では、システム全体を動かすには DB や キャッシュサーバー といった周辺環境が必要です。Dockerを使えば、「Java 21 + Spring Boot 3.x + PostgreSQL 16」という環境一式を「イメージ(設計図)」としてパッケージ化し、GitHub経由でチームに共有できます。他のメンバーは、コマンドを1行叩くだけで、寸分違わぬ同一の開発環境を自分のパソコン内に再現できます。
Docker Desktop と Docker Engine の違い
| 種類 | 対象OS | 特徴 | 開発現場での位置づけ |
|---|---|---|---|
| Docker Desktop | Windows / macOS | GUI (画面) で操作できる高機能パッケージ。裏側でLinuxを動かす仕組み (WSL 2など) も一括でインストールしてくれる。 | Windows/Macを使う開発者の標準ツール。ただし、大企業での商用利用は一部有償化されているため注意が必要。 |
| Docker Engine | Linux | コマンドライン(CLI) だけで動作する、Dockerの「本体(コアエンジン)」そのもの。 | 本番サーバー (Linux) に導入する際の標準。 |
Docker Desktop の導入方法 (Windows)
Docker Desktop の導入方法は以下の通りです。
- WSL 2 の導入
- Docker Desktop のインストール
- 起動確認
WSL 2 の導入
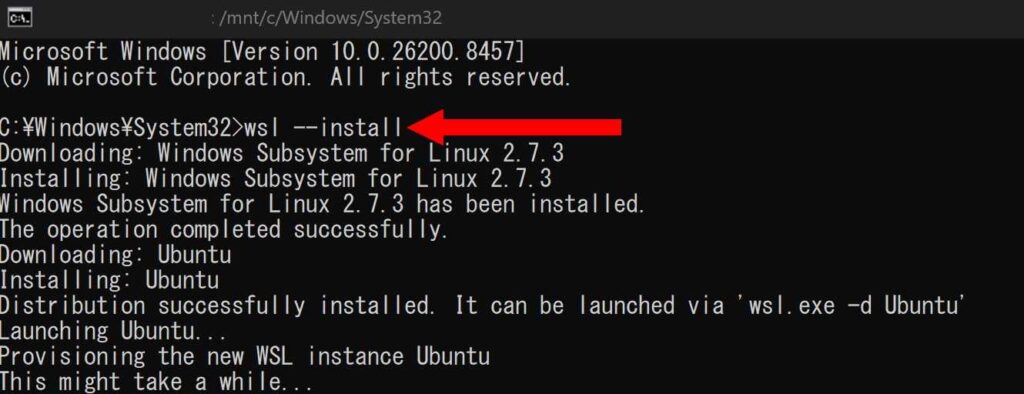
パソコンのコマンドプロンプトまたは PowerShell」を管理者権限で起動します。起動後、wsl –install と入力すると、インストールが始まります。インストールが完了したら、パソコンを再起動してください。
Docker Desktop のインストール
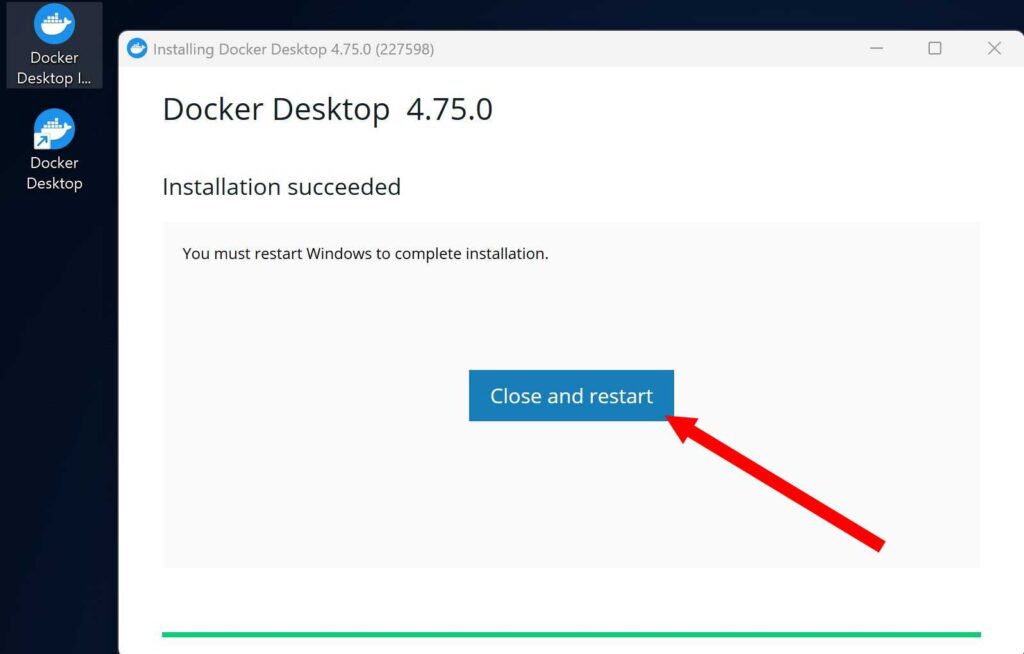
Docker 公式サイトから Docker Desktop のインストーラーをダウンロードしてください。ダウンロード後、インストーラーを起動し、画面の指示通りに進めてください。インストールが完了したら、再起動になります。
起動確認
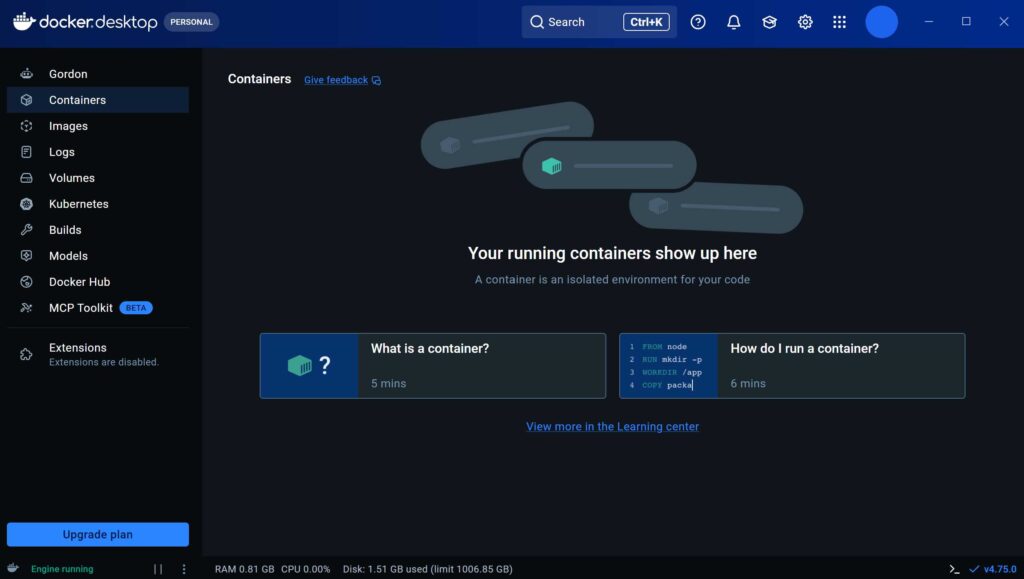
再起動後、Docker の規約に同意し、アカウントを作成します。作成後、起動を確認してください。以上で Docker の導入は完了です。
コマンドプロンプトやターミナルで docker –version を入力し version が出ることでも Docker の導入が確認できます。
クラウドコンピューティング
クラウドコンピューティングとは「自社で高価なサーバー機器を買い揃えてデータセンターに設置する代わりに、インターネット越しに巨大IT企業の強力なサーバーインフラを、必要な時に、必要な分だけレンタルして使える仕組み」です。企業にサーバーインフラを構築することなく、サーバー環境を使用することができます。
インターネット経由で必要な分だけ即座にレンタルできる現代の必須インフラになります。下記が代表的なものです。
| AWS (Amazon Web Service) | 世界シェアNo.1。機能の豊富さと実績が圧倒的であり、Java開発の現場でも採用率が最も高いです。 |
| Microsoft Azure | Windows系システムや、企業のActive Directory (社内アカウント管理) との親和性が非常に高く、大企業の基幹システムで強く支持されています。 |
| GCP (Google Cloud) | データ分析やAI、コンテナ技術 (Kubernetes) に強みを持つ、Googleが運営するクラウドです。 |
Javaシステム構成 (アーキテクチャ)
AWSをベースに、よくある「モダンなJavaシステム構成」の定番パターンを3つ紹介します。
- 仮想サーバー構成
- Dockerを活用する構成
- GitHubと連動した「自動デプロイ(CI/CD)」
仮想サーバー構成
| EC2 (仮想サーバ) |
Webブラウザからのアクセスを「ロードバランサー(負荷分散装置)」が受け取り、複数台のEC2 (Spring Bootが起動しているLinux) へ綺麗に振り分けます。データベースには、クラウド側が自動でバックアップや保守をしてくれる RDS(アールディーエス) という専用のデータベースサービス (PostgreSQLやMySQLなど) を接続します。 |
Javaのプログラム(JARファイル)を、クラウド上の仮想Linuxマシンにそのままデプロイして動かす構成です。
Dockerを活用する構成
| EC2 Fargate ※ コンテナ実行環境 | 開発者は、自分のパソコンのDocker環境で作ったJavaアプリの「コンテナイメージ」を、そのままAWSのコンテナ実行環境 (Fargate) に放り込みます。サーバーのOSレベルの管理をすべてAWSが肩代わりしてくれるため、エンジニアは「コンテナが何個動いているか」だけを監視すればよくなり、インフラの運用管理の手間が劇的に減ります。 |
新規の開発プロジェクトでよく使われます。
GitHubと連動した「自動デプロイ (CI/CD)」
GitHub Actionsとクラウドを結びつけ、人間の手作業によるデプロイ (ファイルをサーバーに手動で転送する作業)をしなくて済むようになります。
- 開発者がJavaのコードを修正し、GitHubのプルリクエストが承認されてMainブランチに合流 (マージ)
- GitHub Actionsが自動起動し、Mavenでビルドとテストを実行
- テストが成功したら、GitHubがそのまま自動でAWS (EC2やECS) のプログラムを最新版に書き換える
Eclipse 関連用語

Eclipse
Eclipse はプログラミングの開発環境ソフトウェアです。IDE という統合開発環境ソフトウェアの1つになります。Eclipse は Java 以外のプログラミングでも使用することができます。Eclipse を使う利点はプログラミング開発、コンパイル、実行がソフトウェア上で簡単に行えることです。
プロジェクト (Project)
Eclipse では「プロジェクト」でプログラミング開発を管理します。
| プロジェクト1 | システム開発1 |
| プロジェクト2 | アプリケーション開発1 |
| プロジェクト3 | システム開発2 |
上の表ではプロジェクト1, 2, 3 としていますが、名前は自由につけることが可能です。プロジェクト1の中に複数のパッケージがあり、それらのパッケージの中には Java クラスファイルが入っています。

コメント